[BOJ_Platinum 2] 10256-돌연변이 [python]
10256번: 돌연변이
인간의 DNA 구조는 A, C, G, T로 이루어진 하나의 긴 문자열로 표현할 수 있다. 이때, 몇 몇 질병은 DNA 구조를 나타낸 문자열의 어떤 연속된 부분 문자열과 관련이 있다는 것이 밝혀져 있다. 만일 DNA
www.acmicpc.net
문제
인간의 DNA 구조는 A, C, G, T로 이루어진 하나의 긴 문자열로 표현할 수 있다.
이때, 몇 몇 질병은 DNA 구조를 나타낸 문자열의 어떤 연속된 부분 문자열과 관련이 있다는 것이 밝혀져 있다. 만일 DNA가 특정 문자열을 부분 문자열로 가진다면 그 질병에 걸릴 가능성이 높다는 것이다. 이러한 특정 문자열을 마커(marker)라 한다.
하지만 때때로 DNA 구조를 그대로 확인하는 것만으로는 질병과 관련된 마커를 확인할 수 없는 경우가 있다. 마커의 돌연변이 가능성 때문이다.
마커의 돌연변이는 아래와 같이 일어난다.
- 먼저, 마커를 세 부분으로 나눈다, 이때, 첫 부분과 세 번째 부분은 비어 있어도 된다.
- 두 번째 부분을 뒤집는다.
예를 들어 마커가 AGGT라면 아래와 같은 여섯 가지 경우가 가능하다.
GAGT, GGAT, TGGA, AGGT, ATGG, AGTG
어떤 사람의 DNA 구조와 마커가 주어졌을 때, DNA 내에 마커가 돌연변이의 형태를 포함하여 몇 번 출현하는지 세는 프로그램을 작성하라.
단, 마커의 출현 위치는 서로 겹쳐도 된다. 예를 들어 DNA 구조가 ATGGAT이며 마커가 AGGT라면 답은 3이 된다. ATGG, TGGA, GGAT가 한 번씩 출현하기 때문이다.
입력
첫 줄에 테스트 케이스의 수 T가 주어진다.
각 테스트 케이스의 첫 줄엔 두 개의 정수 n과 m이 주어진다. 이는 각각 DNA 문자열의 길이와 마커의 길이이다. (1 ≤ n ≤ 1,000,000, 1 ≤ m ≤ 100) 두 번째 줄엔 DNA 구조가 주어진다. 마지막 줄엔 마커가 주어진다.
모든 DNA와 마커는 A,G,T,C로만 이루어진 문자열이다.
출력
각 테스트 케이스마다 주어진 DNA 구조에 마커와 그 돌연변이가 몇 번 출현하는지 하나의 정수로 출력한다.
만일 DNA 구조 내에 마커 또는 그 돌연변이가 한 번도 출현하지 않는다면 답은 0이 된다.
===================================
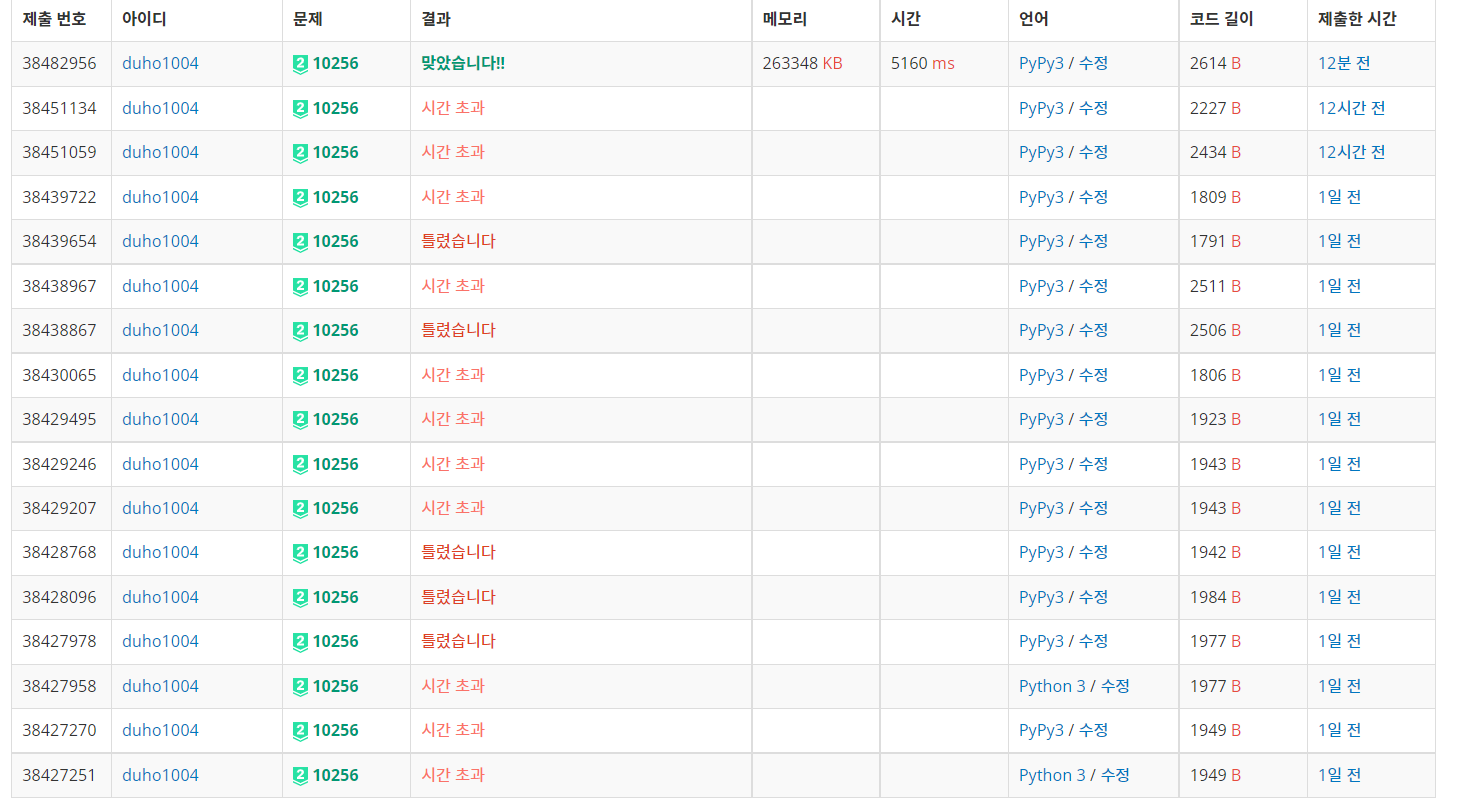
시간 초과와 싸웠던 문제입니다.
Dict로 노드의 Child를 구현하다가, 다른 분의 조언을 듣고 List로 변경한 끝에 해결했습니다.
문제를 풀면서 몰랐던 사실을 새롭게 알게 되었는데,
키를 기반으로 하는 해시의 시간 복잡도가 O(1)이긴 하지만 해시값 연산을 위해, 그리고 구현을 위해 들어가는 시간
(오버헤드)를 감안하면그보다 더 많은 시간이 소요될 수 있다는 점입니다.
리스트는 전체 순회에 O(N)의 시간이 걸리지만 인덱스 기반의 참조에는 O(1)이 걸리고 해시값 연산이 필요한 해시와 달리 오버헤드가 적어 실질적으로 더 효율적으로 동작합니다.
접근할 인덱스 정보를 알고 있다면, 오히려 리스트로 접근하는 방식이 더 효율적인것이죠.
이 내용을 알지 못해 17트만에 겨우 통과하는데 성공했습니다.
문제의 풀이 방법 자체는 간단합니다.
주어진 마커 문자열과 그 변이를 패턴으로, DNA 문자열을 패턴과 대조할 문자열이라고 생각하면,
트라이를 통해 아호-코라식(Aho-Corasick) 알고리즘을 활용해 효율적으로 동작하게 만들 수 있습니다.
이때, 상술했듯 dictionary 자료형을 사용하여 child를 구현할 경우 오버헤드로 인해 시간이 낭비되어 시간 초과가 발생할 수 있습니다. 때문에, 받은 문자열을 정수형 리스트로 변환해주어 돌연변이 생성 시 빠르게 인덱스 접근이 가능하도록 해줍니다.(convStringToInt(String)함수)
시간을 줄일 수 있는 방법은 한가지 더 있는데,
변이가 나타나는 모든 경우의 수를 생각해보면 다음과 같습니다.
i : 변이 시작 인덱스 j : 변이 끝 인덱스 n: 문자열의 길이라고 하면,
변이가 일어날 수 있는 경우의 순서쌍 (i , j)는
(0,1),(0,2),(0,3)...(0,n-1)
(1,2),(1,3),...(1,n-1)
...
(n-2,n-1)
위의 내용을 기반으로 생각해보면, 패턴의 삽입에 있어서 매번 루트 노드에서 시작할 필요 없이
n부터 변이가 시작되는 순서쌍의 경우 n-1번째 깊이의 노드까지는 공통으로 진입해놓고, 나머지 부분에 대해서만 따로 접근해주면 시간을 더욱 더 줄일 수 있습니다.
소스코드는 다음과 같습니다.
import sys
from collections import deque
input = sys.stdin.readline
class TrieNode():
def __init__(self):
self.child = [None] * 4
self.fin = False
self.fail = None
def ConstFail(self):
q = deque()
q.append(self)
self.fail = self
while q:
cur = q.popleft()
for i in range(4):
childNode = cur.child[i]
if not childNode: continue
if cur == self:
childNode.fail = self
else:
f = cur.fail
while f != self and not f.child[i]:
f = f.fail
if f.child[i]:
f = f.child[i]
childNode.fail = f
q.append(childNode)
def Add(self,pattern):
cur = self
for i in range(len(pattern)):
#if i: print("문자열", i, string[:i])
for j in range(i+1,len(pattern),1):
fixedCur = cur
for idx in range(i,len(pattern)): #i / j가 Fix된 나머지 부분은 따로 들어가줘야함
p = pattern[idx] if (idx < i or idx > j) else pattern[j - (idx - i)]
if not fixedCur.child[p]:
fixedCur.child[p] = TrieNode()
fixedCur = fixedCur.child[p]
fixedCur.fin = True
if not cur.child[pattern[i]]:
cur.child[pattern[i]] = TrieNode()
cur = cur.child[pattern[i]]
if i == len(pattern)-1:
cur.fin = True
def Search(self,pattern):
res = 0
cur = self
for p in pattern:
while cur != self and not cur.child[p]:
cur = cur.fail
if cur.child[p]:
cur = cur.child[p]
if cur.fin:
res += 1
return res
""" 트라이 패턴 순회 함수
def Traverse(self,cur,str,dp):
#print(dp)
if cur.fin:
print(str)
return
for c in cur.child:
self.Traverse(cur.child[c],str + c,dp+1)
"""
cvDict = {"A":0,"C":1,"G":2,"T":3}
def convStringToInt(string):
return [cvDict[s] for s in string]
for _ in range(int(input())):
n,m = map(int,input().split())
DNA = convStringToInt(input().rstrip())
marker = convStringToInt(input().rstrip())
Trie = TrieNode()
Trie.Add(marker)
Trie.ConstFail()
print(Trie.Search(DNA))